
Scope
The scope for the new journal will be “The IEEE TRANSACTIONS ON GAMES publishes original high-quality articles covering scientific, technical, and engineering aspects of games.”
Impact Score
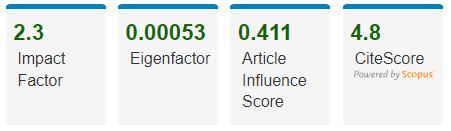
The values displayed for the journal bibliometrics fields in IEEE Xplore are based on the Journal Citation Report from Clarivate from the 2022 report released in June 2023. Journal Citation Metrics Journal Citation Metrics such as Impact Factor, Eigenfactor Score™ and Article Influence Score™ are available where applicable. Each year, Journal Citation Reports© (JCR) from Thomson Reuters examines the influence and impact of scholarly research journals. JCR reveals the relationship between citing and cited journals, offering a systematic, objective means to evaluate the world's leading journals. Find out more about IEEE Journal Bibliometrics.
April 2022 Spotlight Paper
Selected article from IEEE Transactions on Games
Training a Gaming Agent on Brainwaves by B. Francisco, M. Juan, N. Natalia, V. José, R. Rodrigo and S. J. Miguel, in vol. 14, no. 1, pp. 85-92, March 2022.
DOI: 10.1109/TG.2020.3042900.
URL: https://ieeexplore.ieee.org/document/9285187
Error-related potentials (ErrPs) are a particular type of event-related potential elicited by a person attending a recognizable error. These electroencephalographic signals can be used to train a gaming agent by a reinforcement learning algorithm to learn an optimal policy. The experimental process consists of an observational human critic (OHC) observing a simple game scenario while their brain signals are captured. The game consists of a grid, where a blue spot has to reach a desired target in the fewest amount of steps. Results show that there is an effective transfer of information and that the agent successfully learns to solve the game efficiently, from the initial 97 steps on average required to reach the target to the optimal number of eight steps. Our results are expressed in threefold: the mechanics of a simple grid-based game that can elicit the ErrP signal component; the verification that the reward function only penalizes wrong steps, which means that type II error (not properly identifying a wrong movement) does not affect significantly the agent learning process; collaborative rewards from multiple OHCs can be used to train the algorithm effectively and can compensate low classification accuracies and a limited scope of transfer learning schemes.